
こんにちは、ベガコーポレーション データ戦略部 分析基盤エンジニア 新卒3年目の武本です。今回は今まで公開していなかった分析基盤の初期運用について紹介します。
この記事を書こうと思った背景
先日 【データ分析基盤構築】digdag+embulkをFargate運用 という記事を公開したのですが、いきなり大掛かりなものを実装するのは一苦労ですよね。なので、必要最小限でかつ安全にデータ基盤を作るにはどうすれば良いのか? ということを考えると思います。
そこで今回は初期運用をどうしていたのかという部分について紹介しようと思います。
結論
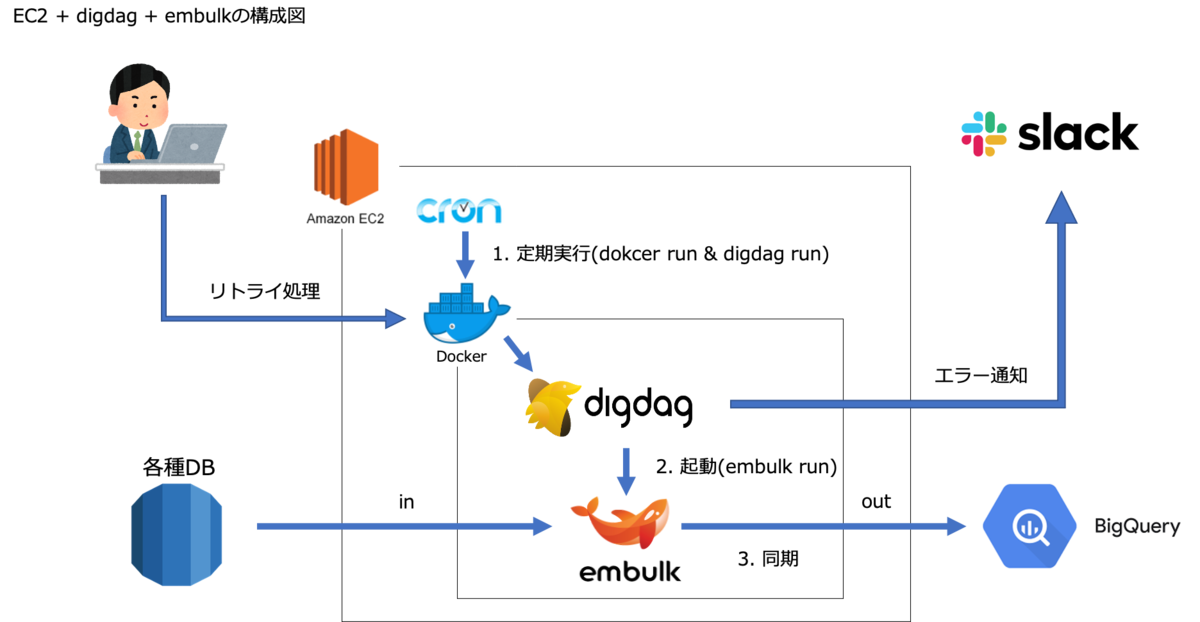
- 定期実行Amazon Linux2のCronでdigdagを実行
- digdagからembulkを実行
これだけです。Digdag UI や Digdag Schedule などの知識を全て省いて、定期実行・フロー管理・データの同期。この3点のみを抑えることにしました。
cronとembulkだけで完結する可能性はありますがslack通知やembulkの細かい設定をするためにdigdagを採用しました。また将来的にはDigdag Serverを運用する想定もあり開発当初から初期運用という感覚でした。
Dockerを挟んでいる理由
本当に最小限の構成にするのであればDockerは必要ありません
壊しても簡単に復旧できる環境が良いと考えたのと、将来的にECSで実行したいという思いがありDockerを採用しました。
最終的にはDigdag Serverを構築することになったので必要はなかったのですが気軽に環境を弄れるという点ではかなりメリットがありました。
デメリットとしてはログの管理が大変だったことですかね。
最小限構築のメリット・デメリット
【メリット】
最小限のコストで実装できる
元々これが目的で構築したので当たり前と言えば当たり前ですが知識ゼロからでも1週間程で構築できてしまう為かなり入りやすいと思います。知識があれば1日で構築できてしまうかもしれません!!システムの説明が容易
特に導入初期頃はどういうシステムなのか? という質問が多く、説明する機会がかなり多いです。説明資料作るにしても複雑なシステムを理解して貰える資料を作るのは一苦労です。他の人に理解して貰いやすいシステムという意味でもメリットがありました。
【デメリット】
安定性の不安
冗長化ができていないという点です。何か障害があったときは実行されない為、データがないと業務が全くできないという現場には不向きなシステムになっています。対してDigdag Server×Fargateの場合は冗長化できている為安定性はかなり上がりました。運用面の不安
実行ログはEC2内に吐き出しを行っていましたがsshしないと見れない状況だった為、エラーチェックは基本Slack通知で行っていました。実行されているかの確認もSlack通知になる為、成功通知もSlackで確認することになります。Digdag serverになってからはDigdag UIで実行ステータスやログを確認できるようになったのでかなり作業がしやすくなりました。
実装方法
Dockerfile
FROM openjdk:8-jre-alpine
RUN apk add --no-cache libc6-compat libc-dev python3 python3-dev coreutils tzdata curl && \
cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \
echo "Asia/Tokyo" > /etc/timezone
# pipをupgradeする
RUN pip3 install --upgrade pip
# pythonのモジュールをインストールする
RUN pip3 install pytz mysql-connector-python google-cloud-bigquery python-dateutil boto3
# py>: でpython3が使えるようにシンボリックリンクさせる
RUN ln -s /usr/bin/python3 /usr/bin/python
# digdag 本体をインストールする
RUN curl -o /bin/digdag --create-dirs -L "https://dl.digdag.io/digdag-latest" \
&& chmod +x /bin/digdag
# Embulk 本体をインストールする
RUN wget -q https://dl.embulk.org/embulk-latest.jar -O /bin/embulk \
&& chmod +x /bin/embulk
# 使いたいプラグインを入れる(embulk-input-mysqlなど)
RUN /bin/embulk gem install embulk-input-mysql embulk-output-bigquery
# 実行ファイルのコピー
COPY ${プロジェクト名}/ /tmp/${プロジェクト名}/
RUN chmod -R +x /tmp/${プロジェクト名}/shell/
# 環境変数設定(必要に応じてデータベースの接続情報を環境変数に格納する)
ENV GOOGLE_APPLICATION_CREDENTIALS "/tmp/${プロジェクト名}/key/project-id.json"
今回はMySQLからBigQueryへの同期をご紹介します。その為に embulk-input-mysql と embulk-output-bigquery を インストールします。必要に応じてインストールするプラグインを変更してください。
定期実行
crontabで任意の時間に以下のようなコマンドを実行させます。
sudo docker run -w /tmp -i /tmp/${PROJECT名}/shell/run_hoge.sh
run_hoge.sh
#!/bin/sh
digdag run /tmp/${PROJECT名}/src/dig/run_hoge.dig --session daily --project ${PROJECT名}/src/dig
--project でファイルのあるフォルダを指定するのが肝だったりします。
digdag + embulk

| 役割 | 説明 |
|---|---|
| 取得テーブルの制御 | embulk実行時のSELECT・FROM・WHEREの制御する |
| embulkの制御 | どのDBからどのDBにデータを移すか(どのプラグインを使うか) |
| データの同期 | embulkの実行 |
フォルダ構成
リポジトリ
├── crontab
├── Dockerfile
├── プロジェクト名
│ ├── shell
│ │ ├── run_hoge.sh
│ ├── key
│ ├── project-id.json(BigQueryのアクセスキーjson)
│ └── src
│ ├── dig
│ │ ├── run_hoge.dig (取得テーブル制御用)
│ │ ├── hoge.dig (embulkの制御用)
│ │ ├── py_arg
│ │ │ ├── source_table.py
│ │ ├── slack
│ │ │ ├── failed-to-sync-table-template.yml (失敗通知用)
│ │ │ ├── success-to-sync-table-template.yml (成功通知用)
│ ├── embulk
│ │ ├── hoge.yml.liquid (データの同期)
│ └── source_table
│ └── hoge.json
取得テーブルの制御
- run_hoge.dig
timezone: Asia/Tokyo
# Slack通知のためのプラグインの読み込み
_export:
plugin:
repositories:
- https://jitpack.io
dependencies:
- com.github.szyn:digdag-slack:0.1.4
webhook_url: https://hooks.slack.com/services/XXX/XXX/XXX
workflow_name: run_hoge_dig
+table_list:
py>: py_arg.source_table.set_table
filename: "../source_table/hoge.json"
+for:
for_each>:
data: ${source_table}
_parallel: false
_do:
call>: hoge.dig
for_each> 取得したいテーブルをfor_eachで切り替える。
_parallel: false スケーリングができていない為、並列処理は無効にします。
- py_arg/source_table.py
jsonファイルを展開してdigdag.env.storeで環境変数source_tableに格納します。
import digdag
import json
def set_table(filename):
f = open(filename, 'r')
json_data = json.load(f)
# 環境変数に設定
digdag.env.store({"source_table": json_data})
- source_table/hoge.json
[
{
"table": "users",
"out_table": "users",
"dataset": "hoge",
"select": "id, name"
},
{
"table": "purchases",
"out_table": "purchases",
"dataset": "hoge",
"select": "id, user_id, purchase_datetime, price"
}
]
| key | 役割 | 必須 |
|---|---|---|
| table | 取得テーブル名 | yes |
| out_table | 挿入テーブル名 | yes |
| dataset | BigQueryのデータセット名 | yes |
| select | 取得したいカラム | yes |
| where | 取得時のwhere句 | no |
embulkの制御
- hoge.dig
+run_embulk:
_retry: 2
_export:
HOST: ${host}
USER: ${user}
PASSWORD: ${password}
DATABASE: ${database}
DESTINATION_DATESET: ${data.dataset}
EMBULK_INPUT_TABLE: ${data.table}
EMBULK_OUTPUT_TABLE: ${data.out_table}
SELECT: ${data.select}
WHERE: "${ typeof(data.where) !== 'undefined' ? data.where : '1 = 1' }"
sh>: TZ=JST embulk run ../embulk/hoge.yml.liquid
# エラー通知
_error:
slack>: slack/failed-to-sync-table-template.yml
# 成功通知
+success:
slack>: slack/success-to-sync-table-template.yml
typeof(data.where) !== 'undefined' ? data.where : '1 = 1' は苦肉の策だったのですがembulkでwhereを指定する場合、''(空文字列)だとエラーになるので'1 = 1'を指定するようにしています。
TZ= の部分は取得DBのタイムゾーンを指定します。設定していない場合は実行環境のタイムゾーンが適応されるので注意が必要です。もしタイムゾーン指定が間違っていた場合はtimestamp型のカラムは時間がずれてBigQuery側に挿入されてしまいます。
slack/failed-to-sync-table-template.ymlとslack/success-to-sync-table-template.ymlは digdag-slackというプラグインに関係しますのでszyn/digdag-slack のREADMEをご参照ください。
データの同期
- hoge.yml.liquid
in:
type: mysql
host: {{env.HOST}}
user: {{env.USER}}
password: {{env.PASSWORD}}
database: {{env.DATABASE}}
table: {{env.EMBULK_INPUT_TABLE}}
select: {{env.SELECT}}
where: {{env.WHERE}}
out:
type: bigquery
mode: [append or replase]
path_prefix: /tmp/
file_ext: .csv.gz
source_format: CSV
project: hoge
dataset: {{env.DESTINATION_DATESET}}
location: location
table: {{env.EMBULK_OUTPUT_TABLE}}
auto_create_table: true
formatter: {type: csv, charset: UTF-8, delimiter: ",", header_line: false}
allow_quoted_newlines: TRUE
encoders:
- {type: gzip}
where: {{env.WHERE}} の部分を以下のようにすれば '1=1' 問題は解決すると教えて頂きました。感謝です!!
{% if env.WHERE != '' %}
where: "{{env.WHERE}}"
{% endif %}
digファイルの WHERE: "${ typeof(data.where) !== 'undefined' ? data.where : '1 = 1' }" を WHERE: "${ typeof(data.where) !== 'undefined' ? data.where : '' }" に変更してください。
まとめ
今回は分析基盤の初期運用について紹介しました。流行りのdigdagを使おうと決めてからかなりの道のりがありましたが、初期運用の頃から重宝しているワークフロー管理ツールです。分析基盤をこれから作りたいという方は是非試して頂けると嬉しいです。